求职招聘是一个双向选择的过程,以往关于人岗推荐任务的研究往往缺少对人岗双边意愿的建模,仅仅是以双方最终是否匹配为预测目标。本文提出了一种联合学习人岗双边意愿与匹配的新型人岗推荐模型IPJF(Interpretable Person-Job Fit)。

该模型利用简历与岗位描述文档,首先预测招聘者对求职者的意愿以及求职者对招聘者的意愿,然后利用在双边意愿预测过程中产生的隐层特征来预测双边最终匹配的概率。基于在线招聘平台BOSS直聘数据集的实验结果表明,本文提出的IPJF模型效果超过state-of-the-art的人岗推荐方法,各评价指标均有显著提升,并且模型具有一定可解释性。实验证明了在人岗推荐问题上引入双边意愿建模可以取得更优的效果。
背景介绍:
面对互联网上存在着的数亿规模的求职者简历以及岗位招聘信息,学习并构建完善的人岗自动匹配推荐系统显得十分重要,这既有助于招聘人员找到合适的候选人,也有助于求职者能够找到合适的岗位。不同于问答(Question Answering)以及检索式对话(Retrieval BasedChat-bot)等信息检索领域经典任务,人岗推荐依赖于招聘者与求职者双边的意愿,是一个双向选择的过程。而现有针对人岗推荐的研究未对双边意愿进行建模,只是对双方最终是否匹配作为研究对象。而实际情况中,解决人岗匹配推荐时意愿信息不容忽视。
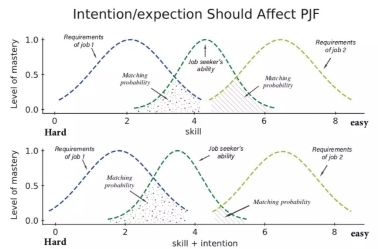
如图所示,在考虑了求职者的意愿信息后,求职者可能与job1更加匹配,这是因为对技能要求更高的岗位往往会有着更高的薪水。对称地,招聘者的意愿对人岗推荐也会有相应影响。
问题定义:
本文将人岗推荐问题定义为排序学习问题(Learningto Rank),包括给定简历文档对候选岗位描述文档进行排序以及给定岗位描述文档对候选简历文档进行排序两种场景。以前者为例,该场景下的候选岗位可分为三种情况:1)求职者主动与该岗位的招聘者发生聊天,并且达成面试约定,这种情况代表了双方均有意愿的正例,标记为‘+’;2)求职者主动与该岗位的招聘者发生聊天,但是双方没有达成面试约定,这种情况代表了求职者单向有意愿的中例,标记为‘0’;3)求职者没有与该岗位的招聘者发生聊天,直接忽视了该候选岗位,这种情况代表负例,标记为‘-’。每一个样本包括一个求职者的简历文档,以及针对它的候选岗位描述文档列表。列表中的每个岗位描述文档可以通过系统日志得到其对应的类别标记(‘+’、‘0’以及‘-’)。在本文的研究场景下,预测意愿的目标是使得简历文档与正例及中例岗位描述文档的分数高于负例,预测匹配的目标是使得简历文档与正例岗位描述文档的得分高于中例和负例。简历文档由多句相关工作经验组成,每个岗位描述文档由多句岗位职责与任职要求组成。对称地,我们可以构建给定岗位描述文档对候选简历文档进行排序这一场景的样本集。
方法描述:
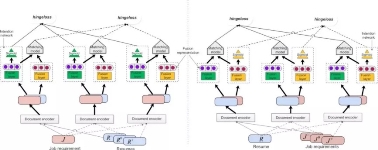
如图所示,我们对给定岗位描述文档对候选简历进行排序(图左),以及给定简历对候选岗位文档进行排序(图右)这两个任务场景同时进行训练。IPJF模型结构包括文档编码器,意愿网络以及匹配网络三个部分。此外,我们还设计了一种“两步-三元组”排序算法来利用模型各部分结构实现对人岗双边意愿以及双方是否匹配的联合训练。
文档编码器(Document Encoder)
给定一个包含p个句子的岗位描述文档和一个包含q个句子的简历文档,
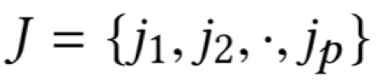
模型首先利用两个卷积神经网络分别对岗位描述文档和简历文档中各句子进行编码,得到矩阵,
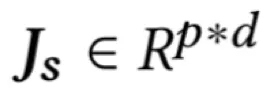
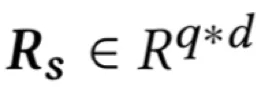
得到了句子表示后,模型利用‘互注意力’(Co-Attention)机制作用于简历文档与岗位文档的两两句子对,得到相似度矩阵A,
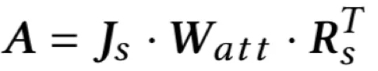
根据相似度矩阵,模型利用岗位描述文档里的一个句子同简历文档里各个句子的相似度之和作为岗位描述文档里这个句子对整个简历文档的覆盖率(Coverage Rate),再对岗位描述文档各个句子的覆盖率作归一化得到一组权重,
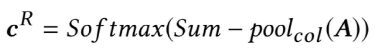
利用这组权重模型对简历文档中各个句子表示加权求和得到简历文档表示,
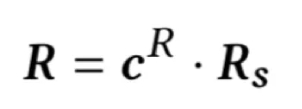
对称地,模型可以利用相似度矩阵和岗位描述文档中各个句子表示计算得到岗位描述文档表示 J。
意愿网络(Intention Networks)
如前文所述,人岗推荐是一个双向选择的过程。因此,我们构建两个对称结构的意愿网络(招聘者意愿网络、求职者意愿网络),以岗位描述文档表示和简历文档表示为输入,分别预测招聘者对求职者的意愿,以及求职者对招聘者的意愿。以招聘者意愿网络为例,整个意愿网络分为融合层(Fusion Layer)和回归层(Regression Layer)两部分,
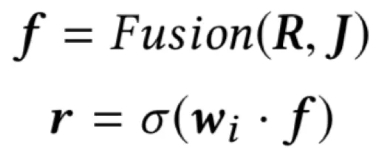
融合层的作用是将人岗双边文档表示整合成意愿隐层特征,为了实现更充分的信息交互,融合层网络采用双线性结构。回归层的作用是利用意愿隐层特征计算招聘者对求职者的意愿程度得分,作为招聘者会主动与求职者发生聊天的概率。融合层输出的意愿隐层特征除了被用来预测意愿程度之外,还将作为匹配网络的输入,因此为了保证其充分携带意愿信息,我们控制回归层的参数量,将其设置为单层逻辑回归结构。
匹配网络(Matching Networks)
匹配网络利用两个意愿网络输出的双边意愿隐层特征作为输入,采用MLP网络预测人岗双方匹配分数,作为双方达成面试约定的概率,
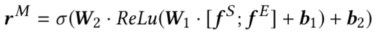
两步-三元组排序算法(Two-StepsTriple-Wise Ranking)
与传统成对排序算法(Pair-Wise Ranking)应用场景有所不同,在本文的人岗推荐场景下,候选列表中的样例分为发生聊天并达成面试约定、发生聊天但没达成面试以及没发生聊天直接被忽视三种情况。此外,在意愿预测时,前两种情况为正例,后一种情况为负例。在预测匹配时,前一种情况为正例,后两种情况为负例。因此,在给定岗位描述文档对候选简历文档进行排序这一场景的训练中,对于每个岗位描述文档,我们从候选集中采样包含正例简历、中例简历、负例简历各一个的三元组,并构建两个损失函数分别作为意愿预测和匹配预测的优化目标,
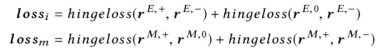
此外,招聘者对候选集合里各个简历对应的求职者发生聊天这一行为只能是招聘者主动发生聊天,因此如果仅考虑给定岗位描述文档对候选简历文档进行排序这一场景去进行训练,模型由于缺少求职者意愿的监督信号,从而无法保证求职者意愿网络输出的隐层意愿特征的质量,这一意愿特征的偏倚现象导致匹配网络无法正常训练。因此,我们将给定岗位描述文档对候选简历进行排序与给定简历文档对候选岗位描述文档进行排序这两个场景来联合训练,从而保证双边输入到匹配网络中的意愿隐层特征的质量。具体地,每次我们采样一个mini-batch的岗位描述文档和它对应的简历文档三元组,以及一个mini-batch的简历文档和它对应的岗位描述文档三元组,构建包含双边意愿以及双边匹配的损失函数,
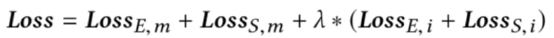
模型采用端到端的方式进行训练,参数更新与计算梯度时,招聘者意愿网络的更新只用了前一个mini-batch的样本,求职者意愿网络的更新只用了后一个mini-batch的样本,匹配网络和文档编码器的更新用了两个mini-batch的样本。
实验效果:
本文基于在线招聘平台BOSS直聘的数据集对所提出的IPJF模型进行验证,比较的方法包括:1)PJFNN:[1]中提出的基于卷积神经网络的匹配模型2)AAPJF:[2]中提出的基于层级注意力机制的匹配模型此外,针对本文提出模型的完整版本(IPJF-JT),我们还实验了两种模型变种(IPJF-SB、IPJF-T)来对意愿与匹配联合训练的有效性,以及将给定岗位文档对候选简历进行排序与给定简历对候选岗位文档进行排序这两个场景来联合训练的有效性分别进行验证。1)IPJF-SB(SingleBranch):不进行任何联合训练,只用文档编码器和分类器去解决每个单任务,分类器的模型结构继承了文中的匹配网络。2)IPJF-T(Transfer):进行意愿与匹配的联合训练,但是单独地解决给定岗位描述文档对候选简历进行排序。为了避免上文中提到意愿特征偏倚现象,模型同时训练单个求职者意愿网络,并将其用在给定岗位描述文档对候选简历文档进行排序的匹配预测中(给定简历对岗位文档进行排序的情况与之对称)。
根据表格中的实验结果,可得如下结论:
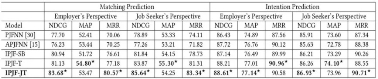
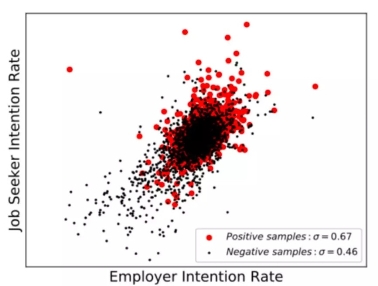
1)从单任务场景下IPJF-SB高于PJFNN以及AAPJF的实验结果可以得出,我们提出的基于‘互注意力’机制计算句子对文档覆盖率,并据此整合句子表示来得到文档表示的编码方式要优于PJFNN中不考虑简历文档与岗位描述文档间信息交互的编码方式,以及AAPJF中仅考虑岗位描述文档对简历文档单向信息交互的编码方式。2)从IPJF-T和IPJF-JT均高于IPJF-SB的实验结果可以得出,我们将意愿预测以及匹配预测进行联合训练要优于单独地训练每个任务。同时可以发现联合训练对于匹配预测的提升相比意愿预测的提升更为明显,而在实际应用场景下,双边匹配的预测具有更大的应用价值,这也显示了本文对意愿预测与匹配预测联合训练的有效性。3)从IPJF-JT高于IPJF-T的实验结果可以得出,将给定岗位描述文档对候选简历文档进行排序与给定简历文档对候选岗位描述文档进行排序这两个场景来联合训练会取得比单独训练其中某一个场景得到更好的效果。除了指标上的比较之外,我们还进一步对本文提出的模型中意愿建模的效果进行解释与分析。我们以给定简历文档对候选岗位描述文档排序这一场景为例,以达成面试约定的简历-岗位描述样本对为正例,以未达成面试约定的简历-岗位描述样本对为负例,将求职者意愿网络与招聘者意愿网络在各个样本对的意愿得分经标准化处理后进行可视化展示,
不难发现,达成面试的正样本的得分相较于未达成面试的负样本的得分更加集中分布于图像的右上方,这显示我们的模型捕捉到了求职双方彼此意愿更强的简历-岗位描述对更有可能成为正样本的现象。此外,我们通过对正负样本集分别计算双边意愿得分的相关系数可以得出,正样本的相关系数显著地高于负样本。这也与实际求职招聘中,人岗任何一方的意愿缺失都会导致不匹配的现象相一致。上述现象也证明了我们的IPJF模型除了取得指标上的提升之外,同时也具有一定可解释性。
来源:华夏小康网
声明:
1、中国周刊网所有自采新闻(含图片),未经允许不得转载或镜像,授权转载应在授权范围内使用,并注明来源。
2、部分内容转自其他媒体,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。
3、如因作品内容、版权和其他问题需要同本网联系的,请在30日内进行。
责任编辑:杨文博


